Debugging a PDH frequency offset
Posted March 6th 2016
Once or twice a year, I debug a network problem which turns out to be caused by a bad synchronisation topology. Here's how I debugged the most recent one.
Symptoms
The direct way to see a frequency offset in a PDH network is to measure the frequency at different interfaces in the network, preferably to an accuracy of at least fractional ppm. The frame rate on an E1 line is supposed to be exactly 8 kHz. But... normally, we see less direct symptoms.
One indirect symptom is clearly visible in the layer 1 counters. Below is a screenshot of normal layer 1 counters for an E1. In cases where there's a frequency offset, you'll see the 'slip +' or 'slip -' counters increasing at a rate of about one per minute, or faster, depending on how bad the frequency offset is.
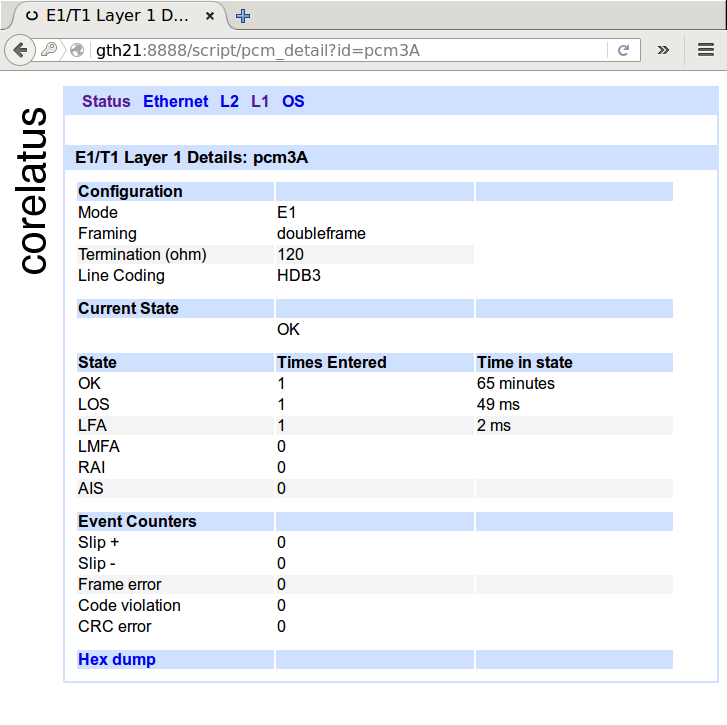
Another indirect symptom is visible in the layer 2 counters of some, but not all, protocols. E.g. in SS7 MTP-2, almost every slip causes a packet to be damaged, so you can see the errored signal unit(ESU) counter increase at a rate of a few per minute. ISDN LAPD, on the other hand tends to hide hide slips, especially at low load.
Analysing a recording
In this case, we could see the SS7 MTP-2 ESU counter increase at an abnormal rate on some timeslots, so I asked for a recording of a couple of minutes of one of the SS7 MTP-2 signalling timeslots which had damaged signalling. Corelatus hardware lets you make bit-exact recordings of live timeslots, either through the HTTP interface or using the 'record' program in the C sample code.
With the recording in hand, I started off by playing it back on a reference GTH 2.1 in our lab, effectively making a copy of the live link in our lab. Turning on MTP-2 decoding, here's what I saw:
| Packet | Time (milliseconds) | Packet dump |
|---|---|---|
| 1 | 0 | 84 9a 00 6c 4d |
| 2 | 134 | 85 9a 00 b0 17 |
| 3 | 2107 | 85 9a b0 17 |
| ... | ||
| 20 | 17921 | 86 a2 00 b6 80 |
| 21 | 22125 | 86 a2 00 86 |
| ... | ||
| 29 | 37351 | 86 a6 00 d6 e7 |
| 30 | 41540 | a6 00 d6 e7 |
SS7 MTP-2 links in normal operation carry nonstop packets: when there's nothing useful that needs to be sent, they send a five octet fill-in signal unit (FISU) over and over again. FISUs are always five octets long and they always have 00 as the middle octet.
Looking at the packet dump, packets 1, 2, 21 and 29 are all valid FISUs. Packets 3, 21 and 30 are all invalid---they are too short to be valid MTP-2 packets and they have incorrect CRCs (frame check sequence). It's pretty easy to see that each bad packet is just like its predecessor, except that one octet has been deleted.
(Aside: if you look closely, the defect in packet 21 isn't exactly a deleted octet. That's because MTP-2 uses bit stuffing and isn't octet aligned. We'll ignore that for now.)
A missing octet is a smoking gun for 'slips'
Having one missing octet in a packet is a smoking gun for a 'negative slip': different parts of the operator's PDH network are running at different frequencies, which forces layer 1 to compensate by throwing out a byte every so often. The missing octet rules out other possible causes for packet damage, in particular bit errors.
At this point, the evidence is already strong, but we can add one more thing to make it overwhelming: look at the elapsed time between damaged packets. We expect 'slip' events to be periodic. Between packets 3 and 21, the elapsed time is 20018ms. Between packets 21 and 30, the elapsed time is 19415ms.
From the elapsed time, we can estimate the frequency difference in the mis-synchronised parts of the network. An E1 timeslot is supposed to carry exactly 8000 octets per second, which corresponds to 125 microseconds per octet. A deleted octet every 20s or so corresponds to a frequency error of 6ppm.
In this case, we're seeing negative slips. The reverse is also possible. In a 'positive slip', layer 1 repeats an octet every so often.
Fixing the root cause
At the time of writing, I don't know what the root cause is. But I can offer a guess based on experience: part of the operator's PDH network has lost contact with the operator's primary reference clock, probably because of a configuration error in one or more cross-connects or MUXes in the network.
A primary reference clock is supposed to maintain long-term accuracy to 1 part per 1011 (ITU-T G.811). The frequency offset we can observe in the spacing of the slips is about 6 parts per 106 (6 ppm), i.e. many orders of magnitude worse than intended.
Permalink | Tags: GTH, telecom-signalling